Extracción y redifusión de la EPA
Lluís Revilla
Recursos
Otros:
¿ Datos ?
Website:
https://www.ine.es/jaxiT3/dlgExport.htm?t=4248&L=0
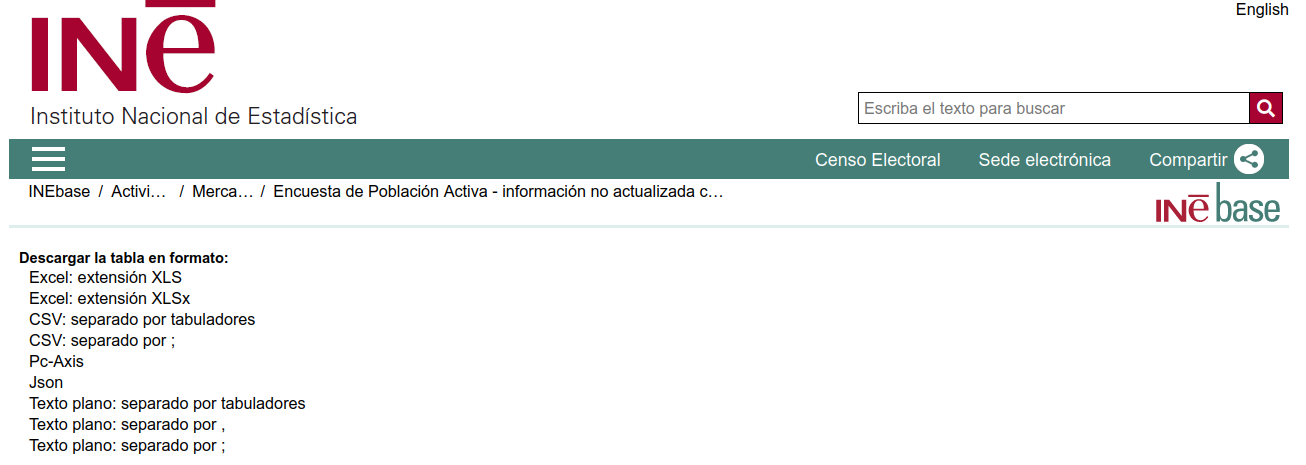
Descargar datos
- XLS: https://www.ine.es/jaxiT3/files/t/es/xls/4248.xls
- XLSX: https://www.ine.es/jaxiT3/files/t/es/xlsx/4248.xlsx
- TSV (\t): https://www.ine.es/jaxiT3/files/t/es/csv_bd/4248.csv
- CSV (;): https://www.ine.es/jaxiT3/files/t/es/csv_bdsc/4248.csv
- Pc-Axis: https://www.ine.es/jaxiT3/files/t/es/px/4248.px
- JSON: https://servicios.ine.es/wstempus/jsCache/es/DATOS_TABLA/4248?tip=AM&
- TSV (\t): https://www.ine.es/jaxiT3/files/t/es/csv/4248.csv
- CSV (,): https://www.ine.es/jaxiT3/files/t/es/csv_c/4248.csv
- CSV (;): https://www.ine.es/jaxiT3/files/t/es/csv_sc/4248.csv
En R
Descargar varios archivos
Descargar ~1000 archivos:
files <- sapply(1:1000, function(x){
# url <- paste0("https://www.ine.es/jaxiT3/dlgExport.htm?t=", x, "&L=0")
url <- paste0("https://www.ine.es/jaxiT3/files/t/es/csv_bdsc/", x, ".xls?nocab=1")
file_path <- paste0("data/", x, ".csv")
download.file(url, destfile = file_path)
if (file.exists(file_path)) {
file_path
} else {
NULL
}
})EPA
EPA website:

EPA screenshot
Descargar EPA
Where is the data?

EPA microdatos screenshot
EPA desde R
download_epa <- function(trimester, year) {
stopifnot(nchar(year) == 2)
stopifnot(nchar(trimester) == 1L)
url <- paste0("https://www.ine.es/ftp/microdatos/epa/datos_",
trimester, "t", year, ".zip")
file_zip <- file.path("data", basename(url))
download.file(url, file_zip)
file_zip
}
EPA_4t23 <- download_epa("4", "23")Cargar los datos
¿Qué hay?
Los datos
CCAA
Provincias
Juntando
Cargar a Google
Data Wrapper
Registrarse en DataWrapper.
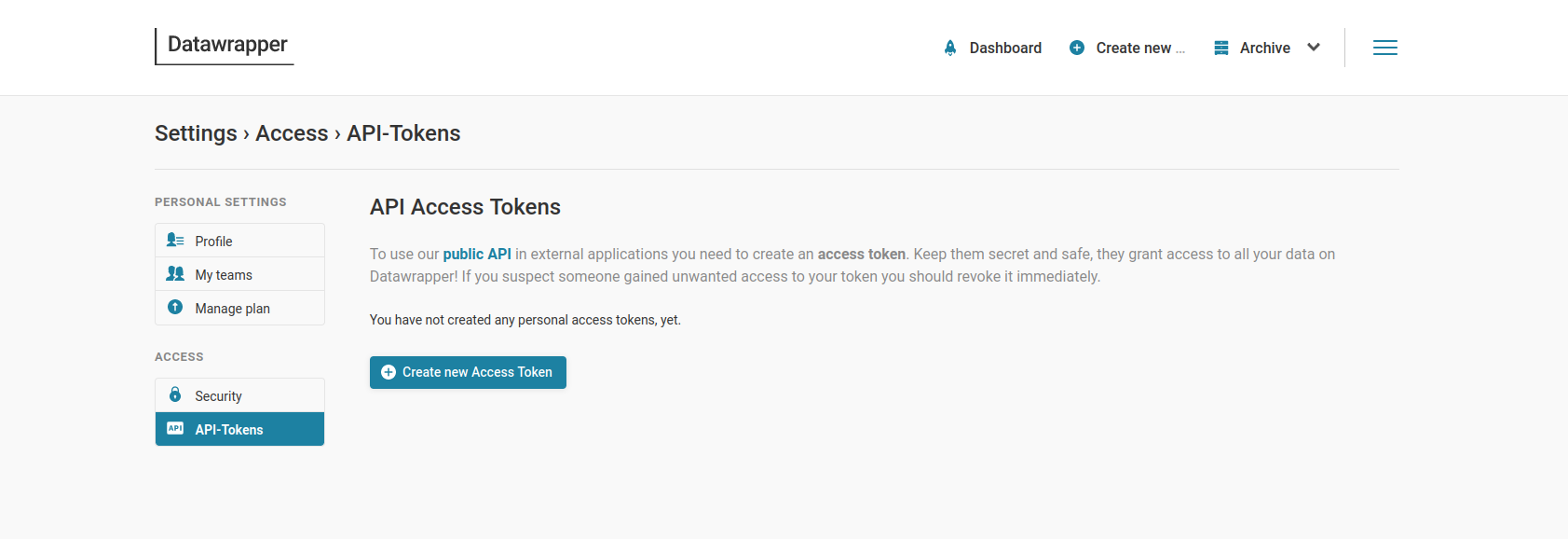
Screenshot for API Access
Cargar de R a DataWrapper
Conectar Google a DataWrapper
En teoria también por:
Usa la web
Si no funciona usa el navegador
Ejercicio
¿Te acuerdas de df?
Comunidades y Ciudades Autónomas Edad Sexo Periodo Total
1 Total Nacional Total Ambos sexos 2023T4 11.76
2 Total Nacional Total Ambos sexos 2023T3 11.84
3 Total Nacional Total Ambos sexos 2023T2 11.60
4 Total Nacional Total Ambos sexos 2023T1 13.26
5 Total Nacional Total Ambos sexos 2022T4 12.87
6 Total Nacional Total Ambos sexos 2022T3 12.67Repite el proceso con estos datos.
Repaso
Otros
¿Acceso fácil y programable?

Operaciones disponibles
ine <- download.file("https://servicios.ine.es/wstempus/js/ES/OPERACIONES_DISPONIBLES",
destfile = "data/operaciones.json")
operaciones <- jsonlite::fromJSON("data/operaciones.json", flatten = TRUE)
head(operaciones) Id Cod_IOE Nombre Codigo Url
1 4 30147 Estadística de Efectos de Comercio Impagados EI <NA>
2 6 30211 Índice de Coste Laboral Armonizado ICLA <NA>
3 7 30168 Estadística de Transmisión de Derechos de la Propiedad ETDP <NA>
4 10 30256 Indicadores Urbanos UA <NA>
5 13 30219 Estadística del Procedimiento Concursal EPC <NA>
6 14 30182 Índices de Precios del Sector Servicios IPS <NA>Publicaciones
publicaciones_url <- "https://servicios.ine.es/wstempus/js/ES/PUBLICACIONES"
download.file(publicaciones_url, "data/publicaciones.json")
public <- jsonlite::fromJSON("data/publicaciones.json", flatten = TRUE)
publications <- list2DF(public)
head(publications) Id Nombre
1 1 Coyuntura Turística Hotelera (EOH/IPH/IRSH)
2 2 Encuesta de ocupación en alojamientos turísticos extrahoteleros
3 3 Hipotecas Mensual
4 4 Indicadores de actividad del sector servicios
5 5 Índices de Comercio al por menor
6 6 Índice de Cifras de Negocios en la Industria
FK_Periodicidad FK_PubFechaAct Url
1 1 10467 <NA>
2 1 10833 <NA>
3 1 10483 <NA>
4 1 10425 <NA>
5 1 10517 <NA>
6 1 10410 <NA>Otras publicaciones
download.file("https://servicios.ine.es/wstempus/js/ES/PUBLICACIONFECHA_PUBLICACION/6?det=15",
destfile = "data/fechapub6.json")
fechas <- jsonlite::fromJSON("data/fechapub6.json", flatten = TRUE)
download.file("https://servicios.ine.es/wstempus/js/ES/PUBLICACIONFECHA_PUBLICACION/7?det=2",
destfile = "data/fechapub7.json")
fechas7 <- jsonlite::fromJSON("data/fechapub7.json", flatten = TRUE)
download.file("https://servicios.ine.es/wstempus/js/ES/PUBLICACIONFECHA_PUBLICACION/8?det=2",
destfile = "data/fechapub8.json")
fechas8 <- jsonlite::fromJSON("data/fechapub8.json", flatten = TRUE)